Kubernetes v1.36 Delivers Production-Ready PSI Metrics for Deeper Resource Monitoring
Since its introduction in the Linux kernel in 2018, Pressure Stall Information (PSI) has given system administrators a precise way to detect resource saturation before it escalates into full-blown outages. Unlike traditional utilization metrics, which can mask performance issues, PSI captures the time tasks spend waiting for CPU, memory, or I/O resources—expressed as percentages. With the graduation of PSI metrics to General Availability in Kubernetes v1.36, users now have a stable, production-grade interface to monitor resource contention at the node, pod, and container levels. This article explores what makes PSI valuable, the extensive performance validation behind its graduation, and what operators can expect.
Beyond Traditional Utilization: The Value of PSI
Relying solely on CPU or memory utilization can be deceptive. A node might display, say, 70% CPU usage while certain tasks suffer severe latency due to scheduling delays. PSI fills this gap by providing two key types of data:
- Cumulative Totals: The absolute amount of time a resource has been stalled.
- Moving Averages: Windows of 10, 60, and 300 seconds that help operators distinguish between transient spikes and sustained resource pressure.
These signals enable proactive capacity planning and faster root-cause analysis, making PSI a critical tool for maintaining cluster health.
Proving Stability: Performance Testing at Scale
A common worry with new telemetry features is the resource overhead they introduce. To address this, SIG Node performed comprehensive performance testing on high-density workloads (over 80 pods per node) across various machine types. The testing aimed to isolate the impact of both the kubelet and the kernel-level PSI collection.
Measuring Kubelet Overhead
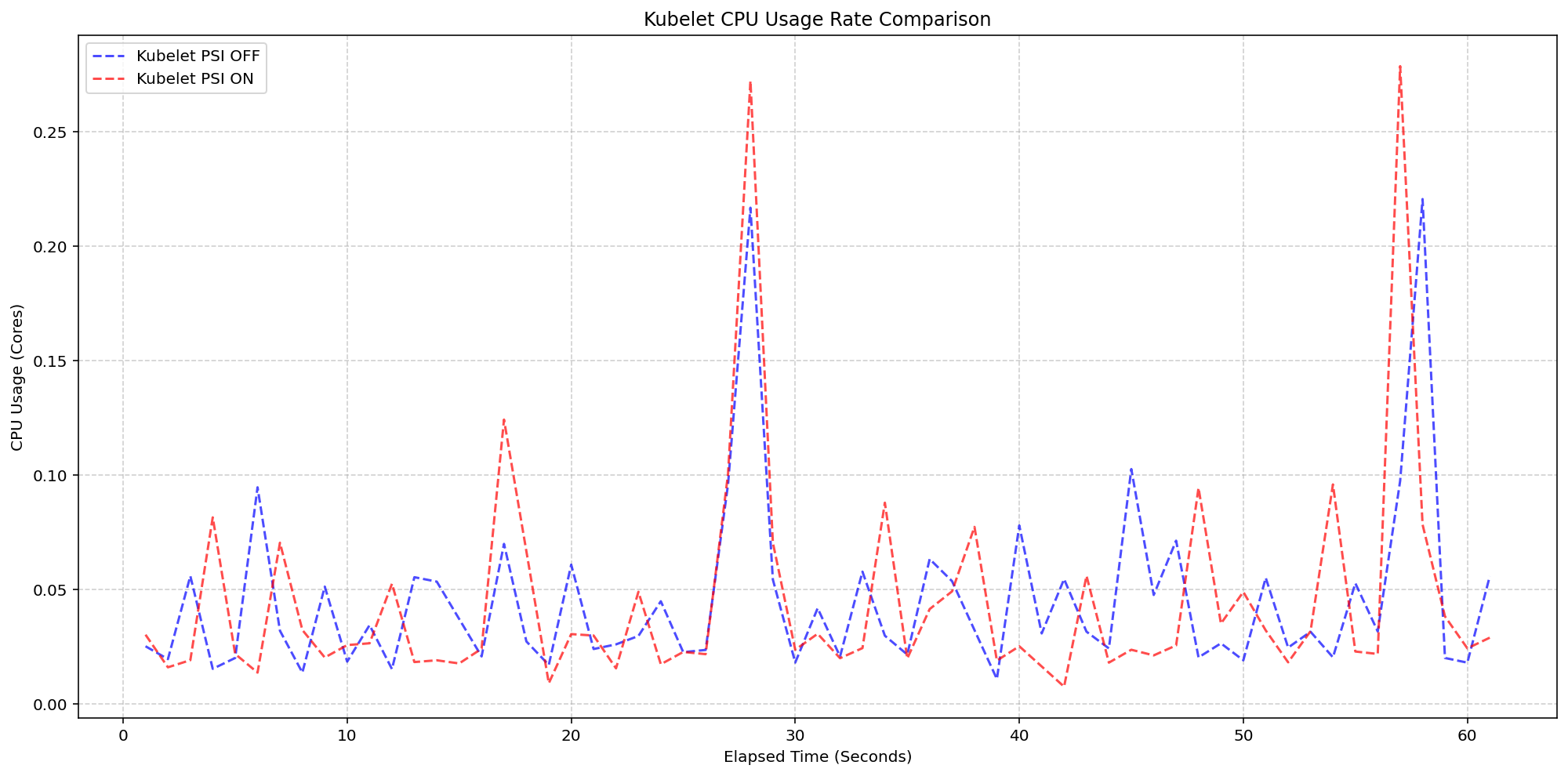
In the first scenario, the kernel was already tracking pressure (psi=1) on both clusters. The KubeletPSI feature gate was toggled on one cluster to observe whether the kubelet actively querying and exposing these metrics added resource usage. The results were clear: the CPU usage patterns of the kubelet were nearly identical between the enabled and disabled clusters, with synchronized bursts matching in magnitude and frequency. The extra collection logic proved lightweight, blending seamlessly into the kubelet's standard housekeeping cycles. The additional CPU consumption remained within 0.1 cores, or 2.5% of total node capacity—well within the margin of safety for production deployments.
Measuring System Overhead
The same test also examined system-level CPU usage. As shown in the performance graphs, the system CPU usage for the kubelet PSI-enabled cluster (red line) closely followed the same pattern as the disabled cluster (blue line), with only a slight expected increase from the baseline. This confirms that once the OS is already tracking PSI—at around 2.5 cores overhead—the act of Kubernetes reading those cgroup metrics adds negligible additional cost.
What This Means for Operators
With PSI metrics now GA, Kubernetes operators can:
- Detect resource contention earlier than with utilization metrics alone.
- Differentiate between transient spikes and sustained pressure via moving averages.
- Optimize resource requests and limits based on actual stall data.
- Improve cluster stability by identifying nodes or pods under chronic stress.
The rigorous performance testing confirms that enabling PSI metrics does not compromise node performance, even under high-density workloads. This makes the feature safe to adopt in production environments without fear of additional overhead.
Conclusion
Kubernetes v1.36 marks a significant milestone for resource monitoring. The graduation of PSI metrics to GA provides operators with a reliable, low-overhead mechanism for observing resource contention across CPU, memory, and I/O. By moving beyond traditional utilization metrics, teams can gain deeper visibility into workload performance and prevent outages before they occur. For more information, see the official Kubernetes PSI documentation.
Related Articles
- Fedora Asahi Remix 44: Everything You Need to Know
- Mastering Fedora Silverblue Upgrades: How to Rebase to Fedora Linux 44
- Mastering AI Hardware Diversity: How KernelEvolve Automates Performance Optimization at Meta
- Platform Engineering's 'Virtuous Cycle' Emerges as Key to Scaling Infrastructure
- Ubuntu 26.10 Gets Surprisingly Bizarre Codename: 'Stonking Stingray'
- Ubuntu Twitter Hacked: Fake AI Agent Tweet Pushes Crypto Scam After DDoS Assault
- 8 Critical Facts About the Quasar Linux RAT Targeting Developer Credentials
- Lubuntu Outshines Linux Mint on Nine-Year-Old Laptop, Changing Expert Recommendations