Accelerating Reinforcement Learning: NVIDIA’s Lossless Speculative Decoding Integration in NeMo RL
The Bottleneck: Rollout Generation Dominates Training Time
If you have ever run reinforcement learning (RL) post-training on a language model for math reasoning, code generation, or any verifiable task, you know the pain of watching a progress bar inch forward while your GPU cluster burns through rollout generation. A team of researchers from NVIDIA has addressed this exact pain point by integrating speculative decoding directly into the RL training loop, preserving the target model’s exact output distribution while dramatically speeding up the process.
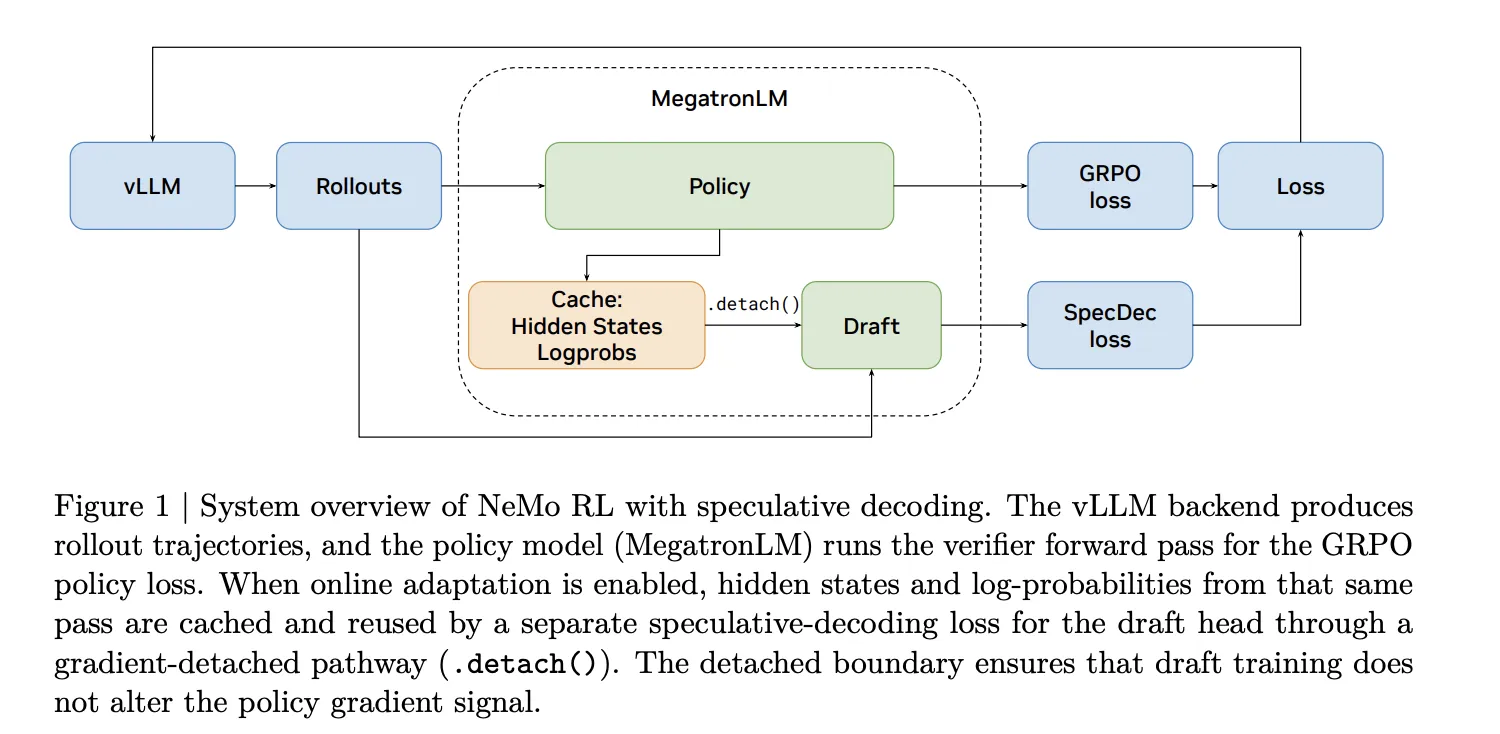
The new feature is now available in NeMo RL v0.6.0, which ships with a vLLM backend for speculative decoding, alongside other updates like the SGLang backend, the Muon optimizer, and YaRN long-context training. The research paper, available on arXiv, details how the team achieved lossless rollout acceleration at the 8B parameter scale and projects even larger gains for 235B models.
To understand why this matters, you first need to look at how a synchronous RL training step breaks down. In NeMo RL, each step consists of five stages: data loading, weight synchronization and backend preparation (prepare), rollout generation (gen), log‑probability recomputation (logprob), and policy optimization (train). The researchers measured this breakdown on Qwen3-8B under two workloads: RL‑Think, which continues training a reasoning‑capable model, and RL‑Zero, which starts from a base model and learns reasoning from scratch.
In both cases, rollout generation accounts for a staggering 65–72% of total step time. Log‑probability recomputation and training together take only about 27–33%. This makes generation the only stage worth targeting for acceleration—and the one that determines the ceiling for any rollout‑side optimization. Speeding it up directly translates to faster overall training.
How Speculative Decoding Works (and Why It’s Lossless)
Speculative decoding is a technique that uses a smaller, faster draft model to propose several tokens at once. The larger target model—the one you are actually training—then verifies those tokens using a rejection sampling procedure. The key property, which makes it uniquely valuable for RL, is that the rejection procedure is mathematically guaranteed to produce the same output distribution as if the target model had generated those tokens autoregressively. No distribution mismatch, no off‑policy corrections needed, no change to the training signal.
This matters because in RL post‑training, the reward depends on the policy’s own samples. Methods like asynchronous execution, off‑policy replay, or low‑precision rollouts all trade some amount of training fidelity for throughput. Speculative decoding trades nothing: the rollouts are identical in distribution to what the target model would have generated on its own, just produced faster.
Integration into NeMo RL: Technical Challenges and Solutions
Adding a draft model to a serving backend is straightforward. Adding one to an RL training loop is not. Every time the policy updates, the rollout engine must receive new weights. The draft model also needs to stay in sync, and the verification step must be tightly coupled to avoid stalls.
The NVIDIA team solved this by integrating speculative decoding directly into NeMo RL v0.6.0 using a vLLM backend. The system handles weight synchronization automatically, ensuring that both the target and draft models always have the latest policy. The verification step is implemented as a rejection sampling loop that runs on the target model, producing exactly the same output distribution as standard autoregressive generation.
The integration also supports the new SGLang backend, giving users flexibility in choosing the serving framework that best fits their infrastructure. The Muon optimizer and YaRN long‑context training are additional tools now available in NeMo RL, but the speculative decoding feature stands out as a direct performance booster.
Performance Results: Measured and Projected Speedups
The research team measured the impact of speculative decoding on rollout generation speed for Qwen3-8B. The results show a 1.8× speedup in rollout generation throughput—meaning rollouts that used to take 100 seconds now take about 56 seconds. Importantly, this speedup is lossless: the final reward and policy behavior are unchanged.
For larger models, the gains are even more dramatic. Projecting the results to a 235B parameter model, the team estimates a 2.5× end‑to‑end speedup for the entire training step. This is because the draft model’s overhead becomes relatively smaller compared to the target model’s computation as model size grows.
The following table summarizes the key findings:
- Model scale: 8B parameters
- Workloads tested: RL‑Think and RL‑Zero
- Rollout generation share of step time: 65–72%
- Measured rollout speedup (8B): 1.8× lossless
- Projected end‑to‑end speedup (235B): 2.5×
Conclusion
Speculative decoding integrated into an RL training loop is a powerful way to accelerate the rollout generation bottleneck without sacrificing training fidelity. NVIDIA’s NeMo RL v0.6.0 now supports this technique out of the box, with a vLLM backend that handles the complexity of weight synchronization and lossless verification. For researchers and engineers working on large‑scale RL post‑training, this is a practical tool that can cut training times by nearly half while keeping the model’s output distribution intact.
For further reading, see the original paper on arXiv or explore the NeMo RL documentation to get started with speculative decoding in your own workflows.
Related Articles
- How the Coursera-Udemy Merger Creates a Unified Skills Platform: A Step-by-Step Overview
- Mastering Java ByteBuffer and Byte Array Conversions: A Step-by-Step Guide
- 10 Hard Truths About Transforming Schools That Nobody Tells You
- 7 Key Enhancements in IBM Vault 2.0 That Transform Secrets Management
- Four Hidden Pitfalls That Sink High-Performing Teams
- Turning the Tide for English Learners: A Step-by-Step Guide to Implementing Orton-Gillingham Literacy Programs
- Your Step-by-Step Guide to Building Job-Ready Skills with Coursera's New Specializations
- Microsoft Launches 11 New Professional Certificates on Coursera: AI, Data, and Development Tracks for the Modern Workforce